去年,研究人员公布了一篇有争议的论文,研究了计算机能否通过分析人类的面部特征,来检测这个人有没有可能是一名罪犯。而如今,来自美国马里兰大学和达特茅斯学院的研究人员最新研发出一套人工智能系统,从面部微表情检测一个人是否在撒谎,结果显示,它的判断准确率已经显著超过了人类的判断水平。
这套人工智能系统名为“欺骗分析与推理引擎”(Deception Analysis and Reasoning Engine,简称DARE),研究人员希望这一系统可以很快地应用到法庭上,来帮助大家辨别法庭上的人是否在陈述事实。
这篇论文发表在学术论文预印本《arXiv》网站。论文写道:谎言在我们的日常生活中很常见,有些谎言无伤大雅,而有些则会造成严重的后果,可能会对对社会产生存在性威胁。例如,在法庭上的谎言可能会影响法官的审判、释放有罪的被告。因此,准确检测高风险情境下的谎言,对个人和公共安全而言都至关重要。
而人类察觉出谎言的能力非常有限。据悉(资料Bond Jr and DePaulo,2006),人们识别谎言与真话的平均正确率只有大约54%。因此,长期以来,人们都认为生理测量法是一种有用的谎言检测方法——测谎仪能够测量出被审问者的一系列生理指标,如血压、心率、皮肤电导情况等,但它们的可靠性仍有待考证。
如测谎仪和近期的功能性磁共振成像(functional Magnetic Resonance Imaging,fMRI)等基础方法并不总是能正确检测出谎言(资料Farah et al, 2014)。此外,这些设备所需的费用以及这种方法的公开性使得这些设备在现实生活中检测谎言的实用性受限。
此外,另一个研究方向是尝试寻找行为线索来检测谎言(资料DePaulo et al, 2003),这些线索往往是一些微小行为的残留,未经训练的人很难辨别出来。例如,根据(资料Ekman et al, 1969; Ekman, 2009),面部微表情能够反映出受试者可能想要隐藏起来的情绪。但是,由于不同的主体有着千差万别,使用计算机视觉也极难检测出这些微表情,尤其是在没有设置约束参数的情况下。
因此,为了开发DARE系统,由喆吴(音译Zhe Wu)博士领导的研究人员特意对AI进行了系统训练,查看大量的法庭视频,让它辨别五种我们已知的、表明某人在说谎的微表情——皱眉头、眉毛扬起、唇角扬起、嘴唇突出和头部侧转。

图1:来自美国马里兰大学和达特茅斯学院的团队特意对AI进行了训练,让它辨别五种我们已知的、表明某人在说谎的微表情——皱眉头、眉毛扬起、唇角扬起、嘴唇突出和头部侧转。
查看过15段法庭上的视频后,研究人员测试了一下DARE系统的辨别能力。结果显示,DARE成功达到了92%的微表情识别成功率,研究人员称之为“表现良好”。
为比较DARE的识别效果,研究人员让人类专业评估者进行了相同的任务,结果只能拿到81%的微表情识别正确率。
研究人员说:“我们的视觉系统使用了高级和低级两种视觉特征,相比人类,能够更好的预测谎言。”而且,如果AI能够收集更多的信息,那么系统可以做到更加高效,譬如,如果另有音频和速记类的补充信息,谎言预测准确性可以得到进一步改善。
DARE系统的自动化谎言检测框架由三步组成:综合特征提取(multi-modal feature extraction)、特征编码(feature encoding)和分类(classification)。
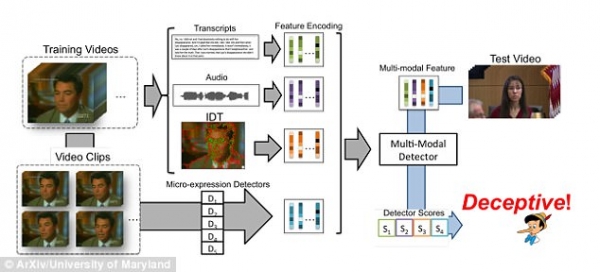
图2:DARE系统的自动化谎言检测框架
前期准备过程中,研究人员在现实生活中的谎言检测数据库中评估了DARE系统的自动化谎言检测方法。这个数据库包含121段法庭审判视频的剪辑,且都是不受约束的网络视频。因此,系统需要从多方面处理人们之间的差异,如拍摄人物的视角、视频质量的变化和背景噪声,如下图。
图3:视频数据
然后研究人员从这121个试验视频数据库中截取104段视频子集,其中包括50段真实视频和54段误导性视频。删减过的视频有着显著的场景变化或人为剪辑特征,且仅包含58种身份,小于视频总量,而且相同的身份往往要么都是误导性的,要么都是真实的。但这意味着,如果同一个人的视频同时覆盖在训练和测试视频片段中,那么谎言识别方法可能更简单,相当于个体身份的再识别,为了避免这种情况出现,研究人员设置了10倍交叉验证身份,而不是仅仅对所有的视频样本进行实验,让测试集中的身份与训练集不相交。
对于每个微表情,研究人员通过使用高级微表情评分功能、低水平的运动特性和其他形态来测试其效力,如下图所示。

图4:预测的微表情(a)& 直接获取的微表情(b)
整个过程中,研究人员使用线性SVM作为分类器。从上图4中我们可以观察到,无论是预测微表情还是直接获取的微表情,“眉头上扬”相比其他微表情都更加有效。“轻轻侧头”对于预测微表情也大有裨益,这不同于我们人眼从表面上获得的微表情。另一方面,“皱眉”在直接获取上要比预测特点更有效,可能是因为“皱眉”的检测器不够精准,如图5所示。

图5:微表情探测器数据分析
为进一步完成这个任务测试,研究人员使用AMT(亚马逊土耳其机器人)完成了用户研究调查。首先,他们请了10位不同的人观看每段视频,并让其表达视频中主题的真实与否。每个注解者都分配到了5个不同身份的视频,以确保没有什么特定的身份偏见会干扰其对谎言的预测。(研究人员还记录了图像、音频或文字本是否有利于用户的决策,如果有需要,人们可以选择多项。)每个视频选票的比例将会作为谎言的一项得分。人类预测的AUC(Area under curve,指统计学的一个模型评价指标)是0.8102。这表明,这个数据集相对比先前的研究更容易预测。
但这还不够,即使是在这样的数据集中,也不能明显判断出这个问题是否具有欺骗性。在做决定时,67.4%的时间用户依赖于视觉线索,61.3%的时间用户依赖于音频信息,而70.7%的时间用户依赖于文本信息,如图6。

图6
值得注意的是,对于每个视频,尽管人们可以任意选择多个模式,但这些数据显示,人们倾向于根据法庭上的口头内容做出判断,因为这是一个语义层面上的特性,另外只有一半的人认为音频有助于他们进行决策。而在DARE系统中,音频特性是非常有效的。
因此,研究人员进行了另一项用户研究。在这一批测试中,每次只为测试者显示一个形态的信息,因为当多个可用的信息来源同时出现时,人们往往很难分辨出哪个信息源最有助于做出最后的判断。为测试人们对每一种形态信息的表现,研究人员请5个人在无声的情况下观看了每段视频,5个人只听了音频,5个人阅读了视频记录。因此在每一项研究中,受试者只能接收一种形态的信息。结果如图7所示,我们可以看到,只有在视觉模态中,人类表现和我们的系统间有着巨大的差距。
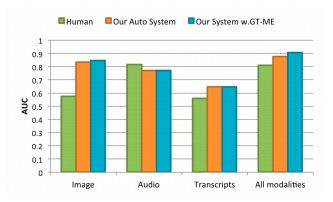
图7:AUC值。绿色表示人类表现,橙色表示自动化系统表现,蓝色表示真实表现
结论表明,人类缺乏单独使用视觉线索预测欺骗性行为的能力,计算机视觉的系统显然更好一些。另一方面,人类只有在音频信息的情况下,判断能力与拥有所有形态的信息时一样好。但只提供视频的文字记录时,无论是人类还是人工智能系统,效用均显著降低。这表明,音频信息在人类预测欺骗性行为中扮演着重要的角色,而文字记录则没有太大帮助。在所有形式的信息中,DARE自动化系统相比一般人的判断准确度要高出约7%,而拥有实况微表情系统的准确性则要高出约11%。
【美国马里兰大学和达特茅斯学院的研究人员关于“DARE系统”的论文Deception Detection in Videos获取方式:关注科技行者公众号(itechwalker),并打开对话界面,回复关键字“法庭测谎”,即可获得下载地址】
来源:DailyMail;编译整理:科技行者
