原标题:从“炒作曲线”看人工智能的苟且与远方
替。

经历了 2016 、2017 上半年的疯狂炒作之后,人工智能的热潮正在褪去。
究其原因,如果按照 Gartner 的「炒作曲线」来解释,则是由于新技术爆发时的公众热度更容易被媒体、资本所捕捉,而随着技术落地过程中暴露出的一系列实际困难,会部分程度上导致公众的悲观,从而让这项新技术逐步淡出公众视野。
人工智能也是如此。在过去的 2017 年,围绕人工智能的场景应用正在成为国内外巨头、创业新贵押注的焦点,然而不管是图像、语音还是自然语言交互,尽管单项技术都不同程度地获得巨大发展,但尚不足以与实际场景结合,形成全新的传播热点,一个显著的案例,AlphaGo 在 2017 年乌镇横扫中国围棋高手的新闻远远不及单挑李世石那样吸引全球关注。
另一个原因,则是更多新技术、新概念的出现,这在中国的表现尤为明显。2017 下半年,特别是 2017 年年底,区块链成为中国互联网行业的「新技术」,这种由虚拟货币所推动的技术几乎「瞬间」占据了投资人、主流科技媒体、各种自媒体的讨论议题里。
上述两个原因或多或少让人工智能暂时摆脱了聚光灯的关注,也让我们有更多的理性去看待这个过去几年被誉为「改变人类命运」的技术,到底是一次面向远方伟大征程的开始,还是又一次从寒冬到盛夏再到寒冬的短暂更替。
人工智能的远方依然令人向往
事实上,关于人工智能的「远方风景」已经被重复了六十多年。自 1956 年「人工智能」一词来到这个星球上,一代代的数学家、计算机科学家都在为之不懈努力,但到底何为「人工智能」却存在太多理解角度。
作为达特茅斯会议组织者之一的约翰·麦卡锡,一直认为「人工智能」一词除了是暗示机器可以去完成人类可以完成的工作之外,和人类行为毫无关系。
而与麦卡锡专注数学逻辑模拟人类大脑的做法不同,另一位达特茅斯的参会者马文·明斯基则早早看到了神经网络的重要性,但颇具讽刺意味的是,也正是明斯基在某种程度上否认了神经网络的可行性,导致基于人工神经网络的研究长期排除在人工智能「主流」研究之外。
而就在麦卡锡离开 MIT,扛起斯坦福大学人工智能研究大旗之时,道格拉斯·恩格尔巴特正在努力将另一种「智能」带入计算机行业。
这位北欧人的后裔并没有麦卡锡的「远大志向」,而是在思考如何将技术去「提升」人类现有的技能,他终其一生都在研究计算机技术至于人类的意义,成为人机交互的「一代宗师」。
在硅谷资深记者约翰·马尔科夫的《与机器人共舞》中,记录了麦卡锡的「人工智能」与恩格尔巴特的「增强智能」之间的恩怨情仇,「在已经过去的50年中,麦卡锡和恩格尔巴特的理论仍然各自为政,他们最为核心的冲突仍然悬而未决。一种方法要用日益强大的计算机硬件和软件组合取代人类;另一种方法则要使用相同的工具,在脑力、经济、社会等方面拓展人类的能力。」
如今,这两种理念在全世界范围内依然有不少支持者。伊隆·马斯克与马克·扎卡伯格口水战,霍金的末日预言与凯文·凯利的批判一度成为 2017 年各大科技媒体争先报道的消息,但这一切讨论却排除了这个领域最有发言权的一线研究者,无论是 Facebook 人工智能实验室负责人 Yan Lecun 还是深度神经网络「教父」般的 Hinton,其冷静而客观的分析,都无法进入大众视野。
另一方面,掌握巨大传播资源的巨头公司则在塑造一个被技术赋能的美好未来。
过去的两年,亚马逊、Google、阿里巴巴等让人工智能走入越来越多的家庭,通过语音交互的智能音箱,语音识别、自然语言处理等技术逐步落地,还让越来越多的用户感受到人工智能的威力;百度、英特尔、Google 还在不断向公众传达自动驾驶的美好未来,那些制作精良又充满未来感的视频不断刷新着公众对于驾驶的所有想象力;一场场科技峰会/发布会上,人工智能正在进入不同行业,它可以让你的手机拍照更好看,它可能是医院医生的助手,它也可以在工厂里为提升产能贡献自己的能力,还会扮演着城市公共安全保卫者的角色......
就这样,这两年内,公众在「人工智能如何帮xxx」的话术中开启新的一天,又在「人工智能将彻底颠覆XXX」的描述中入睡,每隔若干个小时,就有一个新行业被人工智能所改变,每隔若干天,就有一家人工智能创业公司拿了上亿美金的融资,每隔若干月,「自动驾驶即将上路」、「虚拟女朋友」的消息再重复一次。
然而,这一切事关远方的描述,无论是马斯克的人类末日场景还是扎克伯格的乌托邦世界,都跳过了这个行业如今的「苟且」。
当下的苟且:软件、硬件与应用
坦率来说,上文中所有关于「人工智能」进步的说法,都应该换成「深度神经网络」,或者换句话说,过去几年所谓人工智能的进步,都来自深度神经网络的快速发展。
然而,尽管几乎全世界的计算机/互联网巨头都投入到神经网络的研究之中,却依然在处在一个非常初级的阶段,包括以下三个方面:
软件层面:被人寄予厚望的强化学习也难有突破;
硬件层面:群雄逐鹿;
应用层面:图像、语音之外还剩下什么?
先说软件层面。作为 2017 年《MIT 商业评论》评选的年度十大技术,强化学习曾在 AlphaGo 击败各路围棋高手的对弈中发挥了重要作用。强化学习的基本原理,是一种和环境交互过程的「学习」过程,这种动态的学习过程非常适合在一些没有特定规则、实时反馈的场景中,比如工业机器人或自动驾驶。

这是一种令人听起来就激动的机器学习模型,这几乎也是人类学习周遭事物的方式。以驾驶为例,人类司机需要结合路况来实施调整自己的驾驶行为,当下自动驾驶系统中,感知系统可以被深度学习解决,而决策系统和控制系统,则很有可能是强化学习所能发挥作用的领域。
但当下除了 AlphaGo 利用自动对弈进行强化学习之外,其他实际应用并不现实,原因就在于,当这一算法面临现实社会数百个乃至几千个环境变量的挑战时,这种交互过程能否从始至终地保持绝对可控还无法保证,因此,短期内,这个算法还无法真正实现应用。
其次,在硬件领域,针对深度神经网络的竞争日益白热化。英伟达、英特尔、寒武纪、Google、华为、ARM、阿里巴巴 等公司正在紧锣密鼓地推出各种硬件产品——用于训练和运行深度神经网络的高性能、可定制的处理器。
英伟达股价两年内翻了 6 倍,英特尔不惜重金收购的 Nervana、Altera,其目的都是要在这个领域快速成为标准和规则的制定者。但围绕硬件发展路线以及创业路径,依然有诸多不确定性,比如,GPU、FPGA 以及 TPU 还无法有明确的优劣好坏之分,再比如,近两年的量子计算机,又会给机器学习、深度学习带来怎样的变化?
事实上,和其他所有计算行业一样,深度神经网络硬件的最终胜者,一定是那些能提供低价同时强大计算能力、并且能让绝大多数开发者/研究者快速上手的产品,但在 2018 年的现在,我们还看不到。
第三,则是深度神经网络技术落地的关键环节:应用。过去几年,围绕人工智能落地的应用实例时,无外乎有两大领域:
围绕图像/视频的处理,从识别到后期处理,最直接的案例,手机相机的美颜功能;
基于语音的虚拟/实体产品,从手机虚拟助理到智能音箱;
上述两大领域的落地案例在不同行业又有不同的展现形式。在消费端,2017 年华为、苹果都在其新一代旗舰手机中加入 NPU(神经网络处理单元),就是围绕神经网络在处理图像上的能力,用一个单独的处理单元让手机完成大量拍照、图片的处理工作;国内 2017 年出现了一股智能音箱热,其背后的技术驱动力则是语音识别、语义理解、自然语言理解等技术的整合;而在企业端,从 AWS、Google Cloud 到阿里云,云服务商正在将图像/视频的处理能力打包为 API,供开发者和企业调用;垂直领域,基于图像/视频技术,让国内安防行业迎来一个史无前例的春天;也是基于图像/视频技术,医疗影像的变革正徐徐而来......
然而当我们试图寻找上述单点技术之外的落地实例时,却会失望地发现这可能就是故事的全部。毕竟,语音、图像/视频与文本,构成了互联网上的所有内容,整个互联网行业努力的方向,都是要让这些内容最终变成结构化的数据,实现更高效的分析和再利用。
然而,这一切需求的诞生,与其说是一种「增强智能」——技术赋能行业,倒不如说是,这是一种更实际、更功利的选择,让深度学习去解决最有可能解决的问题,并包装为人工智能的福祉,其落脚点还是互联网公司最擅长的领域:数据。
「数据就是石油」,这是最近两年内经常听到一种说法,2017 年一期《经济学人》文章里,有一张图表说明了诸多问题:
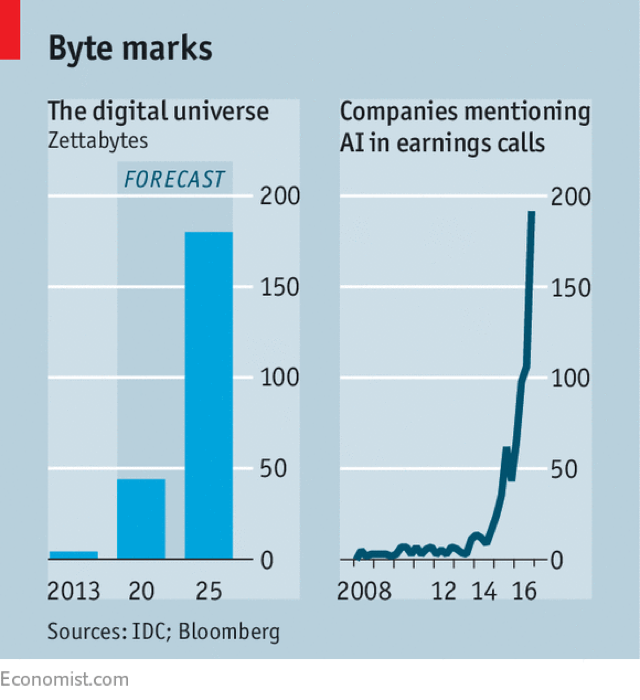
右图是公司财报会议上对于人工智能的关注程度,从 2014 年开始就是极度陡峭的增长线,而与之对应的左图里,IDC 制造的「digital universe」指代的是每年数据生产和复制的数量,其增速也是指数级的。
这至少说明了两个问题:其一,人工智能的确是当下最热的命题之一;其二,人工智能的再次回归,是海量数据带来的最直接反应,这也就不难理解,为何当下所有标榜「人工智能」的应用,几乎都是数据密集领域的产物了。
写在最后,超越不可能
如果以「远方」的标准来衡量当下的「苟且」,深度神经网络远非人工智能的未来。在一个媒体效应远大于实际效应的当下,公众往往会将深度学习、机器学习、人工智能混为一谈;又或者,误以为 AlphaGo 就是深度学习的产物。
我们还在期待更好的算法,从根本上解决「黑盒子」难题,从而可以让机器决策过程变得更透明,这在当下尤为重要。Google 面临欧盟反垄断调查时的首要问题是:为什么这个搜索结果要排在另一个结果之前?再比如,当越来越多标榜将深度学习应用到金融领域的场景里,当用户的贷款请求被深度学习算法所驳回时,能否解释这其中的理由到底是什么?
我们也同样需要一个没有偏见的算法。 2017 年,IBM Watson 在被引入美国法院审判时也出现诸多争议,由于过往数据显示黑人犯罪比例高,导致 Watson 在决策时常常像人类法官一样做出带有偏见性的决策。而在一个男权之上的社会,大量公司高管都是男性,此时倘若引入深度学习作为招聘工具,则很有可能招来更多男性。
这种根深蒂固的偏见几乎普遍存在于所有的机器学习算法中,但很显然,深度学习最难测试与调整,同时又由于其广泛的应用场景变得更加引人瞩目,微软几次三番上线在 Twitter 上线聊天机器人,又几次三番地下架,其原因就是当一个深度学习应用程序面临真实社会场景时,其所做作为已经超出了应用开发者的控制,甚至都无法让其「浪子回头」,唯一的做法就是下架。
你当然可以说这不是算法的问题,而是社会环境的自然映射,可问题的关键在于,围绕人工智能,甚至围绕机器学习,还有大量的选择余地,深度学习不应该、也没有这么大能力承担如此重大的任务,在人类迈向智能社会的伟大征程之中,我们理应有更好的工具。
(本文首发钛媒体 作者:赵赛坡 )
